Introduction#
A tiered storage system will have a hot and cold storage layer. Upon the initialization of the system, the hot layer (or cache) will be empty. This demo will show that prepopulating the cache, with randomly selected geospatial data can improve the long term performance of the system for most applications.
How is this storage system set up?
For this experiment, there are two layers where geospatial data in the form of landsat scenes can reside: the cold storage layer and the hot storage layer. The hot storage layer is constructed as a least recently used cache.
What data is being used?
The data that is used in this experiment are landsat scenes within the continental US. These data cannot be divided, therefore one landsat scene must reside in either the cold storage layer or the least recently used cache.
How is data requested?
Requests for data can be of three forms. A region, a state, or a county. When a request for either of these three sets is placed, the system will determine which landsat scenes encompass the request in its entirety, then move these scenes to the least recently used cache.
What is a least recently used cache?
A least recently used or LRU cache is a cache system which is based on a stack. When data are retrieved from the cache, these data are moved to the bottom of the stack. When new data are placed in the cache, these new data take the place of data at the top of the stack, which is popped off.
Effectively, this means that the cache will maintain data which are frequently requested. Data which was requested the least recently is what will be removed first to make room for new data.
The experiment#
The primary goal of this experiment is to determine what nuances, if any occur when the cache is empty at the start of the simulation and to provide a narrative explanation of why these nuances occur.
The secondary goal of this experiment is to determine under what conditions these nuances will disappear.
To reproduce these results on your machine follow along with the accompanying steps
This project uses Poetry for dependency management. To install all necessary dependencies, follow these steps:
Install Poetry if you haven’t already:
curl -sSL https://install.python-poetry.org | python3 -
Clone the repository:
git clone https://github.com/your-username/Hot-Cold-Simulation.git cd Hot-Cold-Simulation
Install the dependencies:
poetry installGenerate the configuration files necessary to run certain portions of this project.
poetry run generate-config
We will be manually adjusting the configuration files for the two different runs of our simulation. Take note of the
./configdirectory
Simulation 1: Not preloading the cache#
First we will run the simulation with the LRUcache empty to start
Navigate to the
./configdirectory and set the parameters as follows:
cache_param_increment=20
cache_type=LRUCache
hot_layer_constraint=310
num_requests=100
num_runs=8
prepopulate_cache=False
return_type=requests
step_size=0.05
Now execute the simulation with the following command in your terminal
run-analysis
Note: Increasing the
num_runsparameter will decrease noise within your result but will take longer to execute. For a more granular view of different size caches, decrease thecache_param_incrementparameter.
Simulation 2: Preloading the cache#
Now we will prepopulate the LRUcache in its entirety with randomly selected landsat scenes at the start of the simulation
Navigate to the
./configdirectory and set the parameters as follows:
cache_param_increment=20
cache_type=LRUCache
hot_layer_constraint=310
num_requests=100
num_runs=8
prepopulate_cache=False
return_type=requests
step_size=0.05
Now execute the simulation with the following command in your terminal
run-analysis
Note: Increasing the
num_runsparameter will decrease noise within your result but will take longer to execute. For a more granular view of different size caches, decrease thecache_param_incrementparameter.
Results and Discussion#
Under Simulation 1, the highest level of efficiency occurs with a higher proportion of larger sized requests vs smaller sized requests.
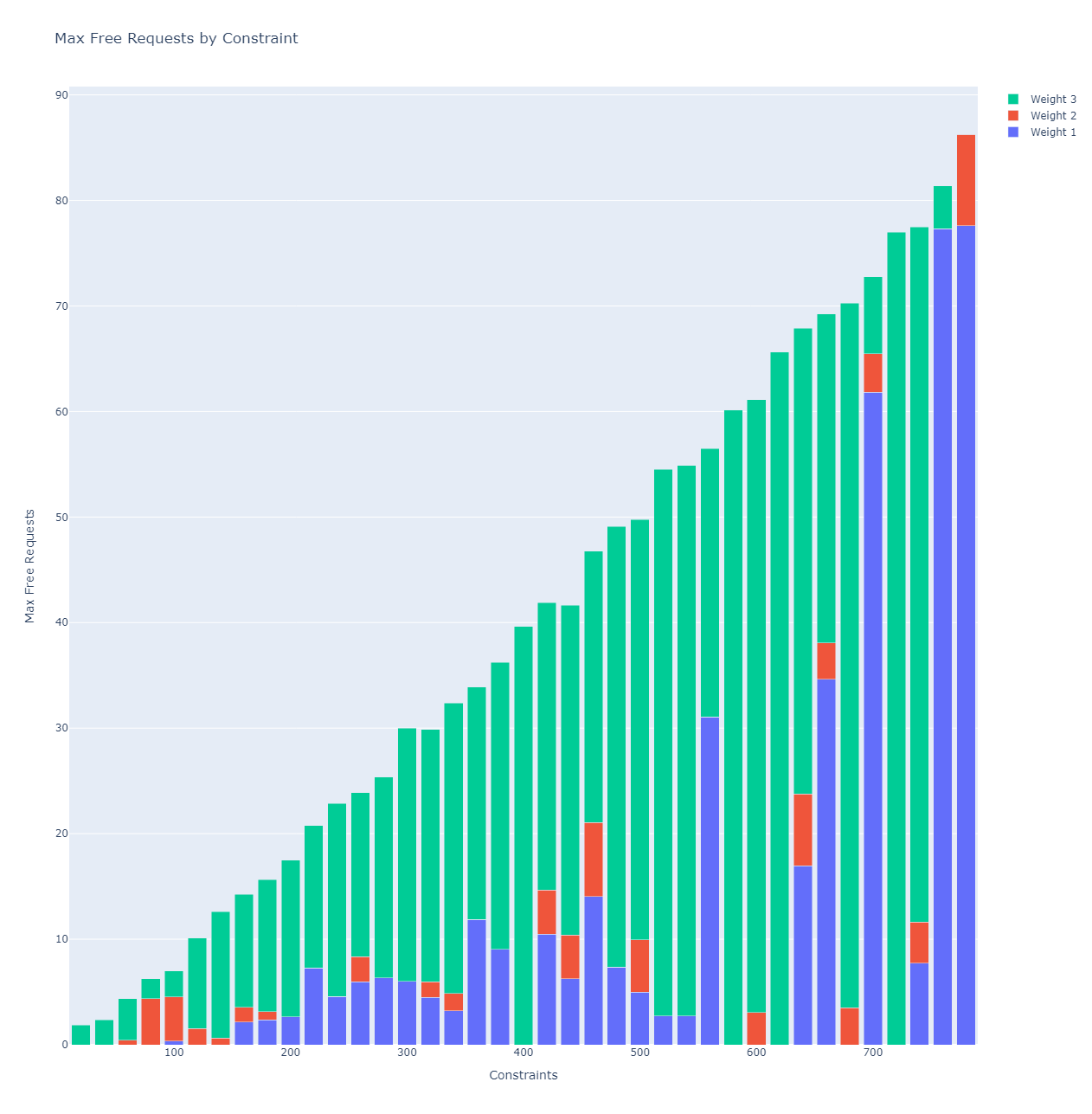
This suggests that as the simulation processes its runs and averages the results, the results are skewed to include more larger requests to maximize efficiency.
This is because the cache is empty to start. The simulation wants the cache to be completely populated as soon as possible, therefore the higher proportion of larger requests will populate the cache to its maximum size more quickly.
Consequently, under Simulation 2, we see that the smallest request size, in this case, counties, results in the highest level of free requests. This intuitively makes sense, as the specific data being requested is uniformly distributed. Therefore if the cache’s data is skewed geographically, i.e. the cache contains one or two regions, efficiency drops.
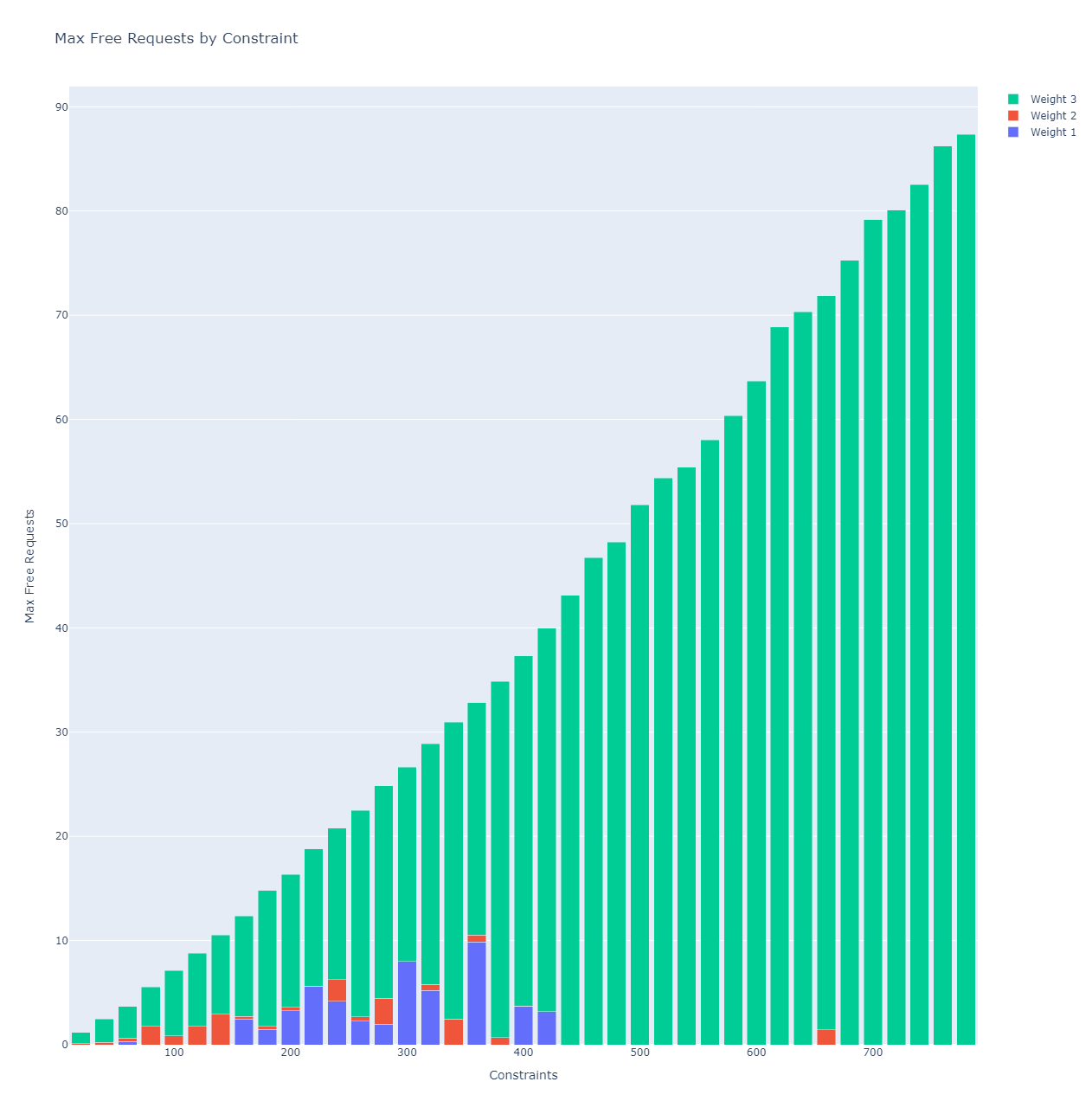
Therefore pre-populating the cache results in the scenario where the highest level of efficiency is obtained under the request parameters most likely to occur in application. This is, when requests for data are small and random. Intuitively it makes sense for a simulation set up with this structure to benefit from a preloaded cache. The key takeaway is that the benefit arises even when the cache is prepopulated with randomly selected data.